Python에서 파일 처리는 데이터를 영구적으로 저장하고 읽어오는 데 필수적인 기능입니다. 이번 포스팅에서는 파일을 여는 방법부터 읽기, 쓰기, 닫기, 그리고 다양한 파일 형식(CSV, JSON) 처리까지 자세히 알아보겠습니다.
1. 파일 열기와 닫기
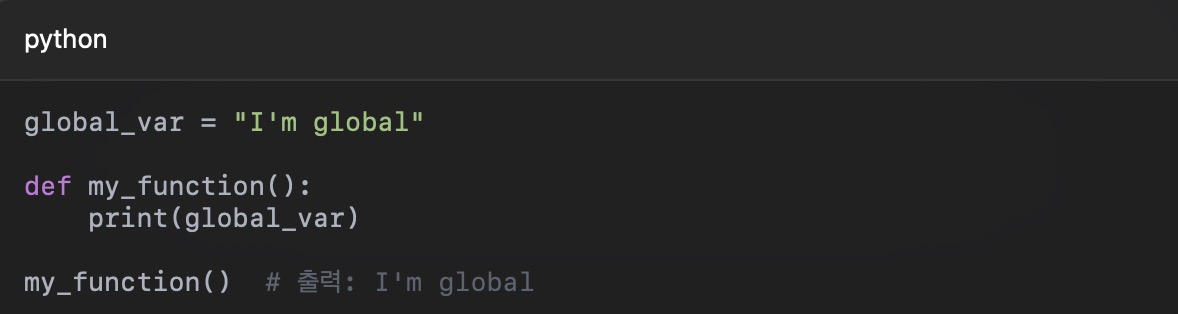
파일을 사용하려면 먼저 open() 함수를 통해 열어야 합니다. 파일을 다 사용한 후에는 close() 메서드로 닫아주는 것이 좋습니다.
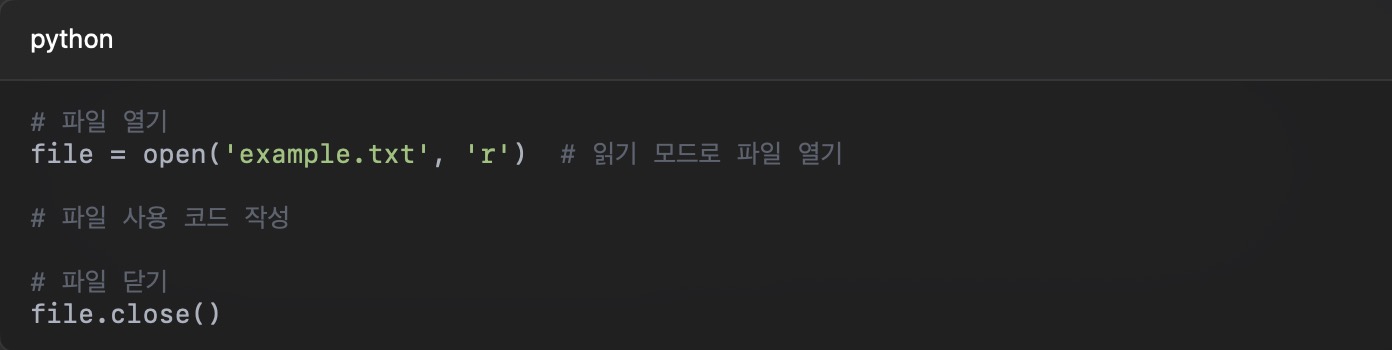
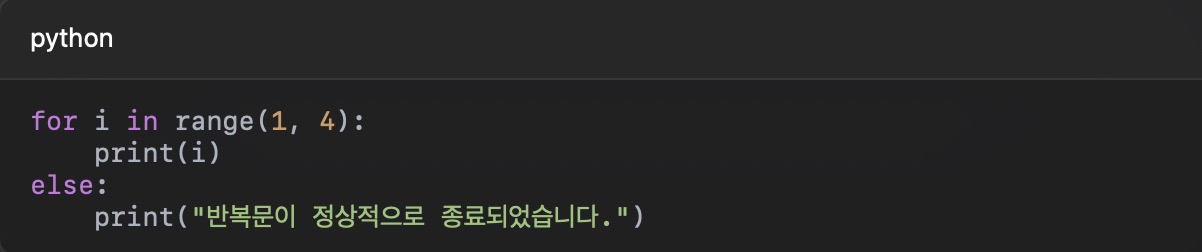
그러나 파일을 열고 닫는 과정에서 예외가 발생할 수 있으므로, with 문을 사용하면 자동으로 파일을 닫아주어 안전합니다.

2. 파일 모드
open() 함수는 두 번째 인자로 파일 모드를 받습니다. 주요 모드는 다음과 같습니다:
• 'r': 읽기 모드 (파일이 존재해야 함)
• 'w': 쓰기 모드 (파일이 없으면 생성, 있으면 내용 삭제)
• 'a': 추가 모드 (파일이 없으면 생성, 있으면 내용 끝에 추가)
• 'b': 바이너리 모드 (예: 'rb', 'wb')
• 바이너리 모드
Python에서 open() 함수의 모드에 'b'를 추가하면 파일이 바이너리 모드로 열립니다.
바이너리 모드는 데이터를 바이트(byte) 단위로 처리하며, 텍스트 인코딩/디코딩 과정 없이 파일의 원본 데이터 그대로를 읽거나 쓸 수 있습니다.
사용 이유
• 텍스트 파일이 아닌 이미지, 오디오, 동영상, 실행 파일 등을 처리할 때.
• 데이터의 원본 상태를 유지하며 읽고 써야 할 때.
• 텍스트가 아닌 데이터는 일반적인 텍스트 모드('r', 'w')로 처리하면 깨질 수 있습니다.
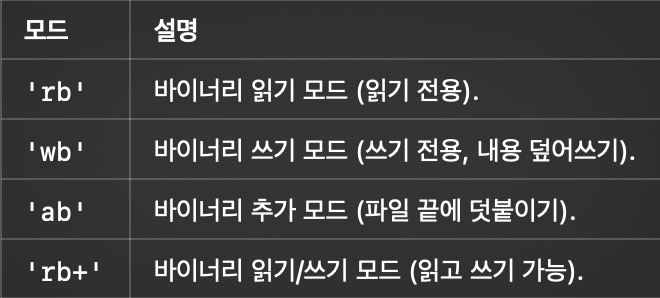
바이너리 모드와 주요 파일 모드의 조합
바이너리 모드 사용 시 주의사항
1. 텍스트와 바이너리 데이터 구분
• 데이터가 바이트 객체(bytes)로 반환됩니다. 텍스트 데이터를 처리하려면 디코딩(decode)이 필요합니 다.

2. 텍스트 모드와의 차이점
• 텍스트 모드는 문자열(str)로 데이터를 읽고 쓰며, 자동으로 인코딩/디코딩을 처리합니다.
• 바이너리 모드는 바이트(bytes) 단위로 데이터를 처리하며, 인코딩/디코딩을 하지 않습니다.
3. 플랫폼 간 차이점
• 텍스트 모드에서는 파일의 개행 문자(\n)가 운영 체제에 따라 변환됩니다. 바이너리 모드는 변환 없이 데이터를 그대로 처리합니다.
4. 파일 크기 확인
• 바이너리 모드를 사용할 때는 파일 크기를 확인하거나 특정 바이트를 처리하는 데 유용합니다.

바이너리 모드가 사용되는 주요 사례
1. 이미지 및 동영상 처리:
바이너리 데이터를 읽고 써서 이미지 파일을 복사하거나 동영상 데이터를 처리.
2. 파일 전송 및 소켓 프로그래밍:
네트워크 프로토콜에서 파일 데이터를 바이트 단위로 전송.
3. 파일 암호화 및 압축:
데이터의 원본 상태를 유지하면서 암호화하거나 압축 작업 수행.
3. 파일 읽기 : Reading a file
1) 전체 내용 읽기
read() 메서드를 사용하여 파일의 전체 내용을 읽을 수 있습니다.

2) 한 줄씩 읽기
readline() 메서드는 한 번 호출에 한 줄씩 읽어옵니다.

3) 모든 줄을 리스트로 읽기
readlines() 메서드는 파일의 모든 줄을 리스트로 반환합니다.

4. 파일 쓰기 : Writing a file
1) 새 파일에 쓰기
쓰기 모드 'w'를 사용하면 파일에 데이터를 쓸 수 있습니다. 파일이 이미 존재하면 기존 내용을 삭제하고 새로 작성합니다.

2) 파일에 내용 추가하기
추가 모드 'a'를 사용하면 기존 내용에 새로운 내용을 덧붙일 수 있습니다.

5. 파일 위치 제어
파일 객체는 현재 읽기/쓰기 위치를 기억합니다. tell() 메서드로 현재 위치를 확인하고, seek() 메서드로 위치를 변경할 수 있습니다.

6. 다양한 파일 형식 다루기
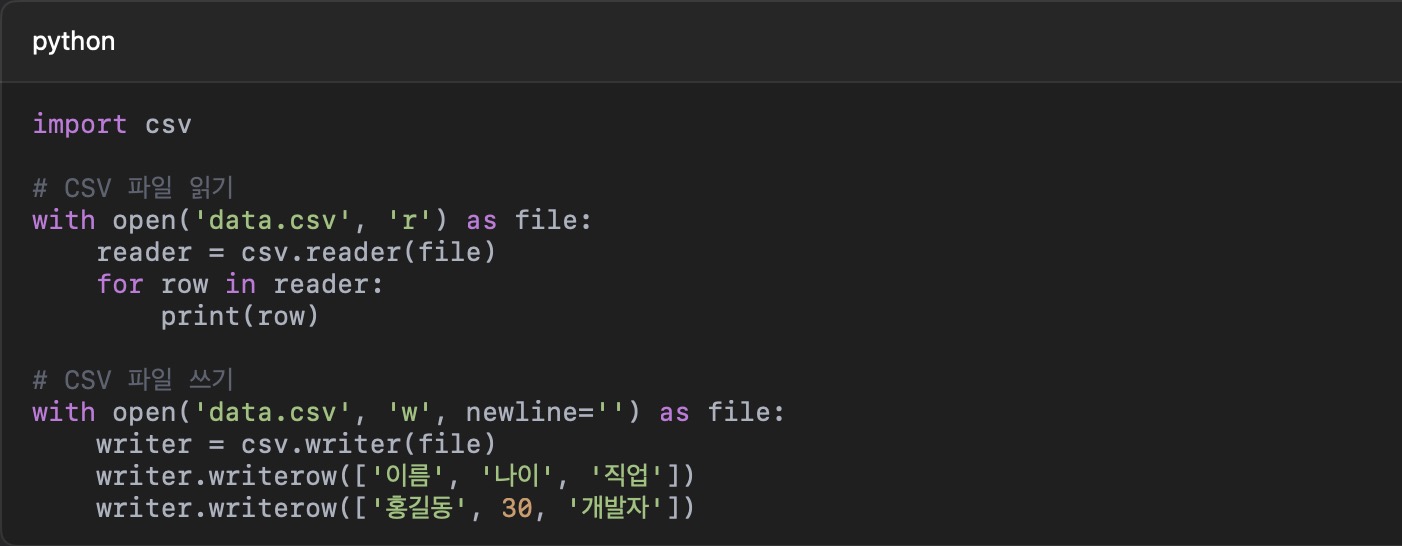
1) CSV 파일
CSV(Comma-Separated Values) 파일은 데이터 저장에 널리 사용됩니다. Python의 csv 모듈을 사용하여 CSV 파일을 읽고 쓸 수 있 습니다.
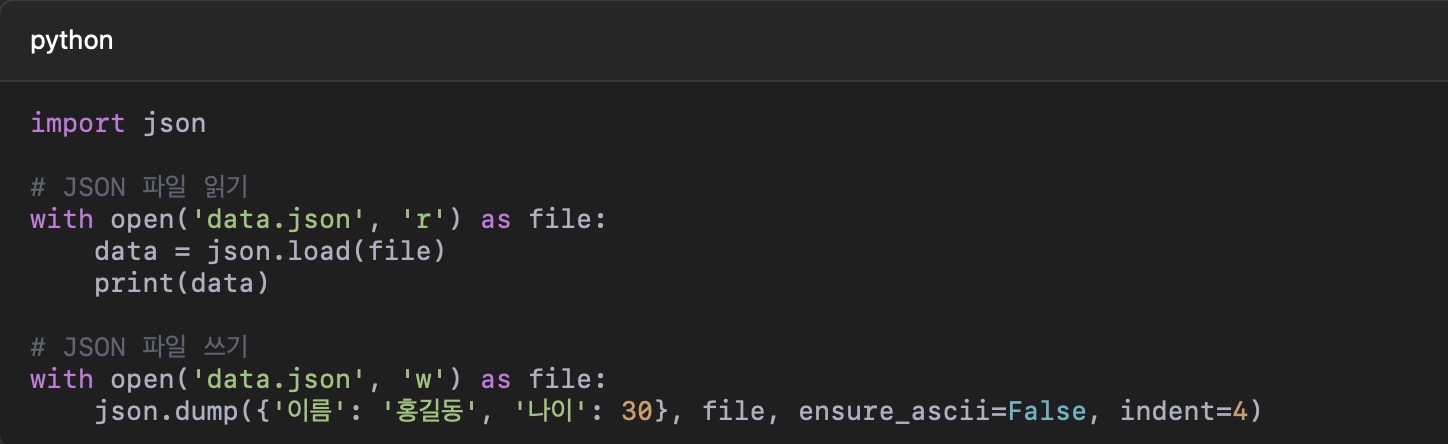
2) JSON 파일
JSON(JavaScript Object Notation) 파일은 데이터 교환에 자주 사용됩니다. Python의 json 모듈을 사용하여 JSON 데이터를 파싱하고 생성할 수 있습니다.
7. 파일 처리 시 주의사항
• 파일 닫기:
with 문을 사용하여 파일을 자동으로 닫도록 하면 안전합니다. 파일을 직접 닫지 않아도 되므로 예외 상황에서도 자원을 효율적으로 관리 할 수 있습니다.
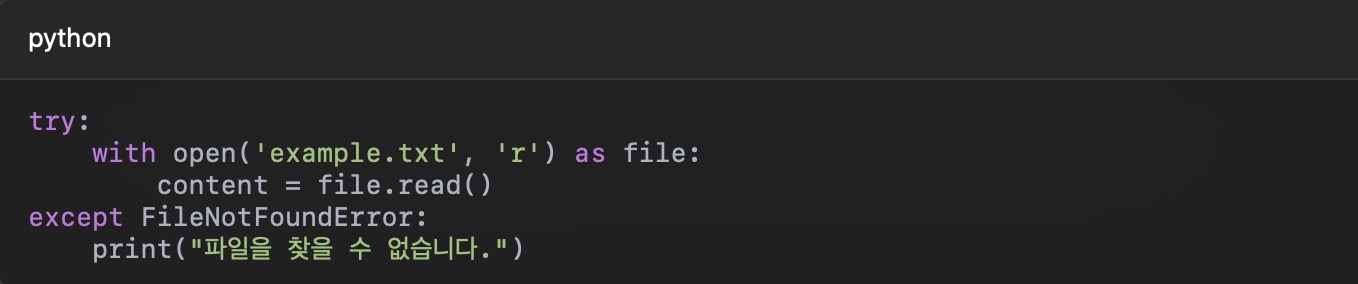
• 예외 처리:
파일 작업 중 예외가 발생할 가능성이 있으므로, try…except 블록을 사용하여 오류를 처리하세요.
• 파일 모드 확인:
파일 작업 전 올바른 모드를 선택하여 데이터 손실을 방지하세요. 예를 들어, 'w' 모드는 기존 내용을 삭제하고 새로 작성하므로 주의가 필 요합니다.
Python의 파일 처리는 데이터를 읽고 쓰는 기본적인 작업부터, CSV, JSON과 같은 구조화된 파일 형식의 처리까지 다양한 작업을 지원합니다. 파일 처리에서 중요한 점은 올바른 파일 모드의 선택과 예외 상황 관리입니다. 이상으로 포스팅 마치겠습니다.
'Language > Python' 카테고리의 다른 글
| <Python>#7 : Python Dictionary : Key-Value Pair로 데이터 관리하기 (0) | 2025.01.06 |
|---|---|
| <Python>#6 : Python Strings : 기본 개념부터 문자열 메서드까지 (1) | 2025.01.06 |
| <Python>#5 : Python Loop : for와 while로 반복 제어하기 (7) | 2025.01.04 |
| <Python>#4 : Python List : 리스트 생성부터 활용까지 (6) | 2025.01.04 |
| <Python>#3 : Python Control Flow : 조건과 논리로 흐름 제어하기 (7) | 2025.01.03 |